The Problem of Knowledge Pollution
- One of the most amazing things about the internet is that millions of people can write helpful articles about anything you want to know.
- One of the most awful things about the internet is that millions of people have written helpful articles about anything you want to know—and left them there, untouched, uncurated, and often obsolete.
This paradox is at the heart of a growing problem: knowledge pollution.

Stale Knowledge in a Living System
The internet was never designed to be a curated library. It was built as a distributed, open system where anyone could contribute. That openness is its strength—but also its Achilles’ heel. Articles from 2012 about how to configure Outlook 2010 still rank in search results. Forums contain answers to questions about software that no longer exists. And AI models, trained on this vast body of knowledge, are now regurgitating these outdated solutions as if they were gospel.
This is no longer just a nuisance for human users who can (sometimes) spot a date and move on. It’s a systemic issue in the age of AI, where models consume everything—true or false, current or obsolete—and synthesise it into answers that may be dangerously misleading.
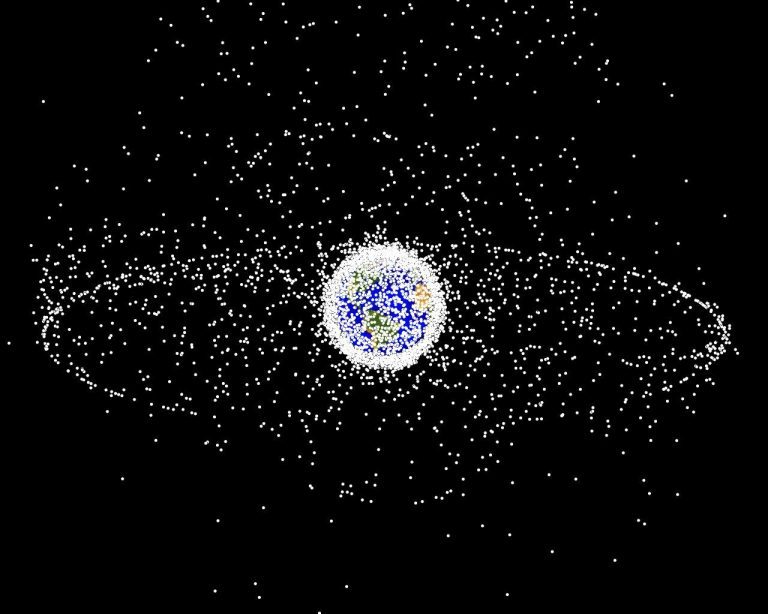
🛰️ A Cosmic Analogy: The Kessler Effect
This digital clutter mirrors a phenomenon in space science known as the Kessler Effect. Proposed by NASA scientist Donald Kessler, it describes a scenario where space debris collides with other debris, creating more fragments in a cascading chain reaction. Eventually, the density of debris becomes so high that space travel becomes nearly impossible.
The internet is experiencing a Kessler-like cascade of content. Every outdated blog post, every abandoned tutorial, every deprecated API guide adds to the debris field. And just like in orbit, the more there is, the harder it becomes to navigate safely.
🌊 Another Parallel: Oceanic Garbage Gyres
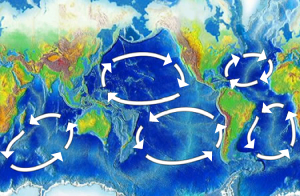
Similarly, the Earth’s oceans have gyres – massive systems of circulating currents that trap floating debris. The most infamous is the Great Pacific Garbage Patch, a swirling vortex of plastic waste that’s nearly impossible to clean up.
The web has its own gyres: search engines, content aggregators, and AI models that trap and recirculate outdated knowledge. Once an article enters the system, it rarely leaves. It floats, it fragments, and it accumulates.
Real-World Examples of Outdated Knowledge
Here are some common examples of outdated content that continue to pollute the digital knowledge ecosystem:
🖥️ Technology & Software
- Tutorials for configuring Outlook 2010 or Windows Live Mail.
- API documentation for retired services like Twitter v1.1.
- Stack Overflow answers referencing deprecated libraries (`urllib2`, `var` in JavaScript).
- Instructions for UI elements that no longer exist (e.g., Gmail Labs).
🌐 Web Development
- CSS hacks for Internet Explorer 6.
- HTML tutorials using “ tags.
- JavaScript examples using outdated practices.
📱 Mobile & Apps
- Android rooting guides for devices from 2014.
- iOS jailbreak tutorials for iOS 9 or earlier.
🧪 Science & Health
- Nutrition advice based on outdated research (e.g., low-fat diets).
- Medical advice referencing discontinued treatments.
💼 Business & Finance
- Tax advice based on old legislation.
- Investment strategies referencing outdated market conditions.
🧳 Travel & Culture
- Travel blogs referencing closed attractions or outdated visa rules.
- Cultural etiquette guides based on stereotypes or outdated norms.
And these are just a few … there are, quite literally, millions of other examples and more each day.
A Way Forward: Knowledge Management Theory
In the corporate world, Knowledge Management (KM) is a mature discipline that deals with how organisations create, share, use, and retire knowledge. Applying KM principles to the internet could help us manage this growing problem.
Key KM Concepts That Could Help:
- Knowledge Lifecycle Management
Content should have a lifecycle: creation, validation, use, and retirement. - Metadata and Contextual Tagging
Articles should carry rich metadata: creation date, last verified date, applicable software version. - Knowledge Curation and Stewardship
Platforms could appoint stewards—human or AI-assisted—to maintain high-value content. - Feedback Loops and Crowdsourced Validation
Users should be able to flag outdated or incorrect content. - Digital Knowledge Hygiene
Promote practices that encourage creators to update or remove stale content.
The AI Angle: Garbage In, Garbage Out
Final Thoughts
The internet is the greatest repository of human knowledge ever created. But without intentional management, it risks becoming a digital landfill—overflowing with once-useful information that now obscures more than it reveals.
We need to treat knowledge as a living asset, not a static artifact. That means building systems that can curate, clean, and retire information—before the weight of our own wisdom collapses under its own gravity.
Knowledge pollution is a real thing and will keep growing until we learn to get it under control.